

Column Definition - Avoid Mistakes Early in SQL
Tutorial on SQL constraints.

If you work with data, you have seen many of these SQL table-creation codes:

This is a basic column definition for the Employees table. Each column must have a data type, so the above is the minimal requirement.
Beginners usually stop there, and they pay later with their time. Creating tables without more constraints can cause many headaches in data management.
I will show you the better option, and then we will break it down:

Why constraints matter
The second example has some constraints added to the table. Columns without constraints can cause some issues:
Data Quality
A column might contain invalid or incomplete data. We don’t wantNULLin ourEmployeeID.Duplicates
Duplicate values in a column can lead to errors in joins or unique identification. Without constraints, the ID can contain duplicates.Logical errors
A column could contain logically invalid values. We don’t want a negative salary in theSalarycolumn.Performance issues
Searching or sorting through columns with poorly defined data can be slow.
Without constraints, every application interacting with the database must implement its version of data validation, logical error correction, etc.
Tables without constraints will delay the work to be done. We cannot work with the errors above, we need to address them somewhere. Why don’t we do it then early, when it is the easiest?
There are different types of constraints, let’s check them each.
DEFAULT clause
When the system doesn’t have a value to put into the column, then it will use the value defined in DEFAULT
For example, for the DepartmentID we have DEFAULT 1. This means that If you add a new employee but omit the DepartmentID in the INSERT statement, the database automatically assigns the value 1 to the DepartmentID column.

The above will result in:
EmployeeID | Salary | DepartmentID
------------------------------------
101 | 50000.00 | 1
This can be especially useful if most employees are from Department 1, so we can simplify the Insert query.
DEFAULT can be strings, numbers, or boolean, but you can use some more advanced expressions and functions as well:
The below will automatically record the time of insertion without requiring explicit input.

Here are some best practices for DEFAULT:

NOT NULL constraint
NOT NULL ensures a column in a table cannot contain Null. Generally, you should add it to all the columns and only remove it if necessary. Nulls can cause a lot of trouble, so getting rid of them at step zero is a good idea.
Since we added the constraint to the EmployeeID, insertion of a row without a value for EmployeeID will fail.
INSERT INTO Employees (Salary, DepartmentID) VALUES (50000.00, 1);
-- Error: EmployeeID cannot be NULLCHECK() constraint
This constraint allows you to define logical conditions that must be satisfied for a row to be inserted or updated. In our example Salary DECIMAL(10, 2) NOT NULL CHECK (Salary > 0) ensures that we cannot insert a negative salary or 0.
The constraint accepts rows when the search condition returns TRUE or UNKNOWN.
Wait, What is UNKNOWN?
It usually happens when we are working with NULL in the check.
The way we create the table below ensures that the Bonus cannot be bigger than the Salary, but we can have NULL inserted. As you can see, CHECK can use different columns in the condition.
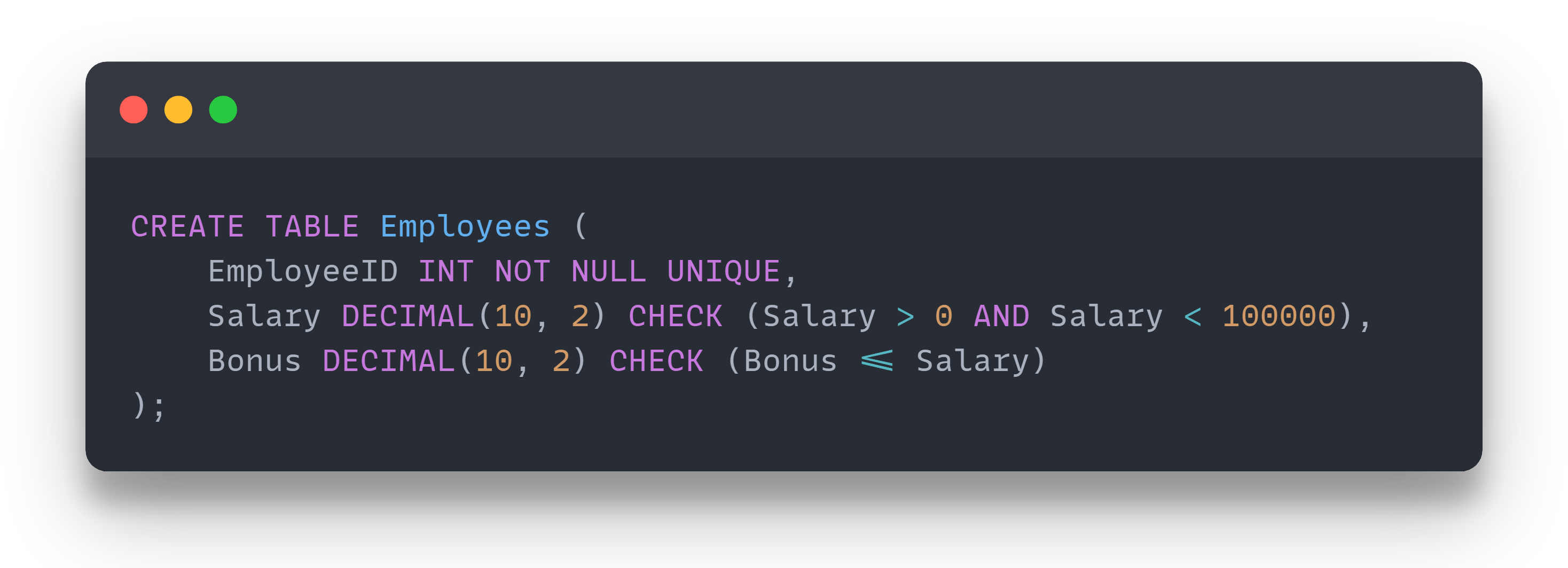
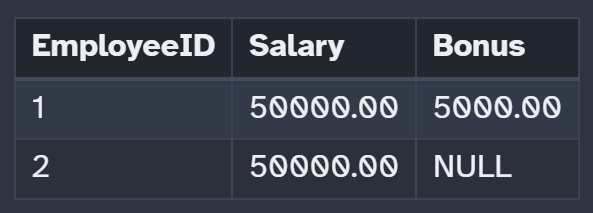
If we insert with NULL bonus the row will still get accepted.
INSERT INTO Employees (EmployeeID, Salary, Bonus)
VALUES (1, 50000.00, 5000.00);
-- Accepted: Salary > 0 AND Salary < 100000, and Bonus <= Salary
INSERT INTO Employees (EmployeeID, Salary, Bonus)
VALUES (2, 50000.00, NULL);
-- Accepted: CHECK (Bonus <= Salary) evaluates to UNKNOWN
INSERT INTO Employees (EmployeeID, Salary, Bonus)
VALUES (3, 50000.00, 60000.00);
-- Error: CHECK constraint failed (Bonus <= Salary)
This is the resulting table:
UNIQUE constraint
UNIQUE ensures that no duplicate values are allowed in the column. UNIQUE allows NULL values (there can be multiple - two NULL values are not equal) unless combined with NOT NULL.
When the UNIQUE constraint is applied, every new row is checked to ensure that the value in the column doesn’t already exist in the table.
If you use DEFAULT + UNIQUE, you must ensure that the value remains unique with every new row.

In this case, only one department can have the name 'General'.
You can define a UNIQUE constraint across multiple columns to enforce unique combinations of values:

This ensures that an employee cannot be assigned to the same project more than once.
PRIMARY KEY
PRIMARY KEY acts as the main unique identifier. Even though they are similar, there are some subtle differences between UNIQUE and PRIMARY KEY:

We have one more clause, namely the References in the example, but more on that in the next post!