

Data Lake, Warehouse, Fabric - What is the difference?

When we work with data it is really important to understand the sources. There are many options available and I wanted to learn about them.
I found a video with James Serra, an expert in Data Architecture, and this rabbit hole is deeeeep. I scratched the surface for you, so here are my notes from the video and his blog:
Data Warehouse
We don’t want to access the data directly from its sources. These sources can be customer information, product information, or purchase data from the same system/app, but they may be in different locations. We need a copy of the data in one place, and we store this copy in the DW.
The DW will be the single version of truth for historical data. We don’t want to run reports or analyses on the sources directly.
A DW is optimized for reading, meaning that it is easier to pull data from it than from the source systems. The source systems are usually optimized for writing, meaning that it is easier to input the data.
Source systems are usually not self-explanatory, but we can restructure and rename tables and fields, so data becomes more organized in a DW.
A DW is schema-on-write, meaning the data’s structure is defined and enforced when the data is written into the system. Before you load data into the DW, you must decide what tables you need, their columns, data types, and relationships. When data comes in it must adapt to this schema.
Data quality and consistency are high because you’re controlling what goes in. Changes in the source systems will not cause issues in reports or analyses.
DWs are for all areas like Finance, HR, and Sales, and the data in them is very detailed, while Data Marts are built on DWs and contain only single subject area subsets.

Data Lake
A Data Lake is schema-on-read. You can load any kind of data raw and unstructured, in its original format. You define the schema when you read or query the data, not before.
DLs are good for storing huge data at low cost. You can put in it everything “just in case” you need it later. You may never touch a part of it.
You can explore if the data is useful or not before making the first modifications on it. It may be the case that it turns out that the data is not useful at all, so no waste of time and cost in processing it.
It can handle large files quickly and can be useful also for archiving the data.

Modern Data Warehouse
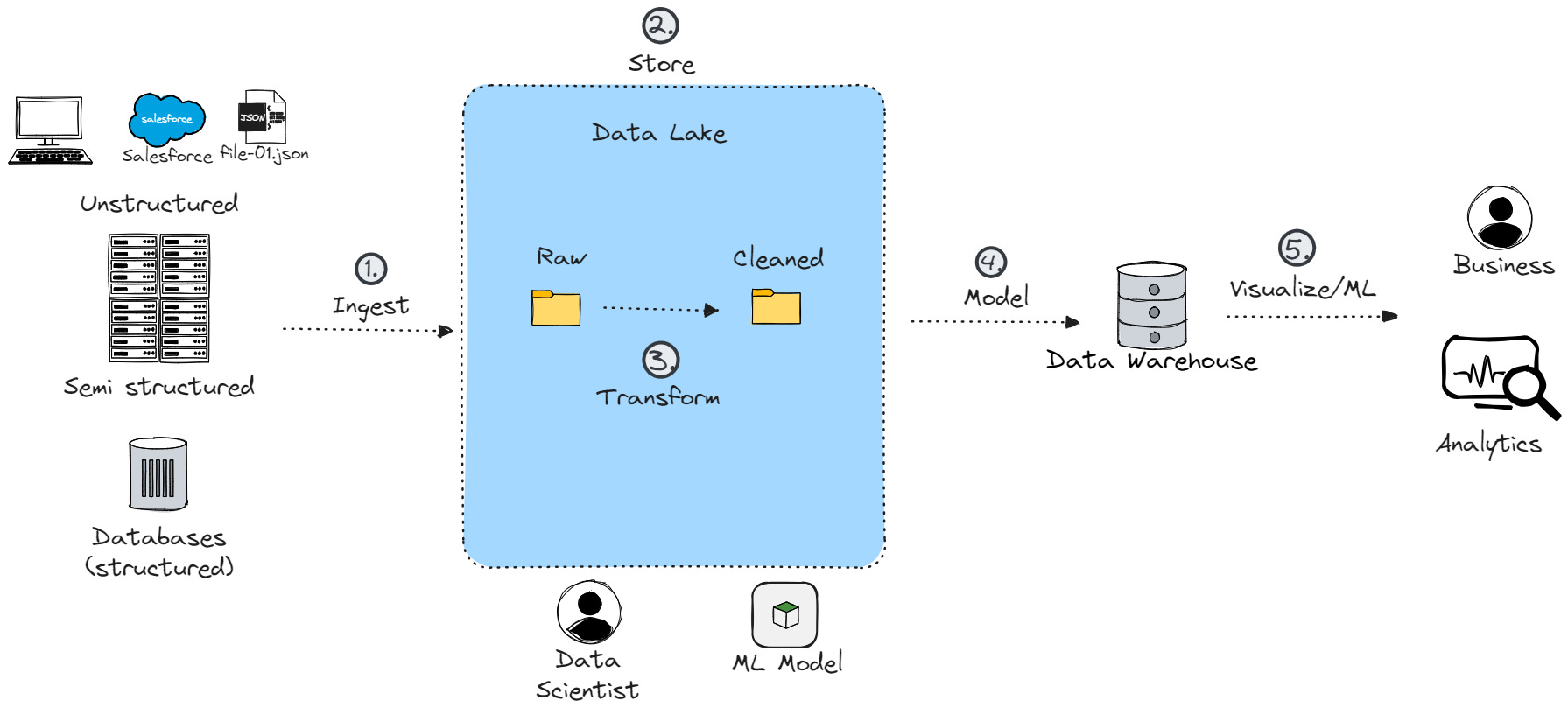
In the MDW we combine the two structures above and it has 5 major steps:
Ingest
Store - Data Lake
Transform
Model
Visualize/ML
In the first step, we import the data from many sources into the lake in raw format.
In the MDW concept, the data is cleaned in the lake, so steps 2 and 3 are happening simultaneously. We will have raw data and a clean data layer in the lake.
Some end users, like Data Scientists, can already access data from the lake. For other users, the cleaning happening in step 3 may not be “clean enough”.
Step 4 models the data and puts it into a relational data warehouse. In some cases even star schema is created, so the analytics/reporting team could work with the data more easily.
In step 5 end users can drag and drop data fields into reports or do analytics since all the joins and preparation are done at this stage.

Data Fabric
Data Fabric adds functionality to the MDW.
For example, we can add an API to our cleaned data, or use advanced security features for the Data Lake and Warehouse.
It is an additional layer on top of our existing MDW.
Data Mesh
Decentralization is a buzzword nowadays. Data cannot be a niche where we don’t use it.
Date Mesh is a decentralized data architecture. It is not a technology, but a concept. All the domains could use the same data lake, hence the lake would become decentralized.
In a Data Mesh, each domain has ownership over its data, and they make it available to other domains as a product. This can lead to a lot of chaos, so ideally, there is a central IT team that helps to create standardized processes for each domain.
A great Data Mesh is hard to build and it could take years. You need the whole organization to be on the same page for their data architecture decisions.
Which to use?
There are no clear ‘if this then that’ answers to this question. It depends on the industry, budget, and people, but mostly the size and type of the data. As you can see from the notes above, the architecture gets more and more complex and their capacity increases as well.
You can also have a combination of all the above.
Sources:
https://www.jamesserra.com/