

How to anonymize data

I’m working on a project where I need to anonymize data. I have no experience in it, so let’s learn about it together:
Identifiability spectrum
When we anonymize data, we want it to be different from the original format, so it is not easy to recognize or identify. But it has levels. Some anonymization techniques will only make it harder to recognize the original data, while others make it impossible.
For example, if you know the stock ticker of a company is ‘GOOGL’, then you know that we talk about Google (or in this case, the company behind it: Alphabet Inc.). This ticker is a direct ID.
Indirect IDs are like the CEOs of a company. If you know only the fact that Elon Musk is the CEO of the company, then you need another identifier to limit the companies to one.
As you move further down on this spectrum, you will find it harder and harder to get back to the original data, and at the end, we have totally anonymized data that we cannot identify.
Other aspects to consider
Identifiability is probably the most important aspect in anonymization (btw, typing this word kills me…), but other things we should consider:
Data should be analyzable
Reversibility
Live or static
Deterministic or nondeterministic
When we anonymize data, we don’t want to lose the ability to analyze it. For example, if a dataset has correlation in it, then we cannot randomly change the data and lose its statistical features.
For internal use, you probably want the anonymization to be reversible. But for external parties, you usually must make the data unidentifiable, so end users cannot reverse it back to the original format.
Live anonymization is when you are not changing the entire data, only the subset that you want to access at a time. For static anonymization, data is already stored in the anonym format.
And finally, a deterministic method is where A is always changed to B. In a nondeterministic method, A can be B in the first run, but C in the second run.
Now that we know about the aspects to consider, let’s see the techniques we can use.
Generalization
When we generalize, we replace a value with a less specific but consistent value.
For numbers, you can use ranges, and for categorical data, you can use a broader category:

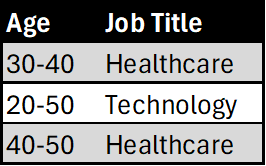
You can also level them:

Suppression
In this technique, we make the data invisible. We either remove it or keep it, but hide it.
If we extend the example above and add gender to the table:

And then we suppress the gender column, we get this:

You can apply all these techniques conditionally or combined with other techniques.
Distortion
We use this technique mainly with numerical data. The original data is distorted by noise. For example, we can add a random number to each value. The formula to use can be super simple, but complicated as well.

We would need to remove the Original Salary column, but I left it here for easier understanding.
If we want to keep the option to analyse the data, the distorted values must be plausible.

The above table applies a bad distortion and makes the salary implausible.
The salary can’t be negative, the Nurse and Cardiologist salaries are unrealistic, so an analysis of these data would be misleading.
Swapping
In swapping, we simply change the values between records:


The goal is to make the sensitive value unlinkable to the individual. Swapping must be controlled, because the data can be misleading again if we make it randomly.
It is more useful for homogeneous groups. Like within a category, you can more easily swap the subcategory.


Now we cannot link the person to the original job, but the context is still logical.
Masking
Masking replaces part of a data value with a placeholder but keeps the format:

It is great if we want to keep the pattern recognizable, so the readability stays in the data.
It is a super broad and really interesting topic. We just scratched the surface, but I might go deeper into it later. See you there as well.